大家好,我是一宵三筵
鐵人賽已經開跑了,我這邊今年是第一次參加鐵人賽
那鐵人賽就是會存一些草稿嘛,每天再把文章發出去就行
但可能就會遇到一個問題...
「如果我忘記發文怎麼辦?」
或是我看到有些問答,也會討論說可能出國去了,或是有事真的需要設排程
在此希望iT邦幫忙可以出排程發文的功能... 如果有我就不用那麼辛苦了
總之我沉思幾秒鐘,就決定來做自動將草稿發文的程式了
我這邊要先聲明,我不會寫Python
平常最常接觸的語言是JS/TS、React、nodeJS
jQuery和php也會,但就是不會python
所以以下的程式,是一邊問ChatGPT一邊寫出來的
之後是怎麼從0到有的研究過程,會放在我的鐵人賽系列文中!
這邊推廣一下我的鐵人賽文章: 用ChatGPT詠唱來完成工作與點亮前後端技能樹
我真的用詠唱學python,從安裝到裡面各種語法 (哭泣)
最後花了兩天時間寫完~
OK教學正文開始:
首先,我已經將程式放上github了: github連結
最核心有關發布、取得列表資料的部分,這邊也可以進行複製utils.py
import requests
from bs4 import BeautifulSoup
import re
from urllib.parse import urlencode
from configparser import ConfigParser
config = ConfigParser()
config.read('itHelpConfig.ini')
lineToken = config.get('Settings', 'line_token')
# 建立session
def getSession(cookie_value = ''):
session = requests.Session()
# 設定 User-Agent 標頭
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/117.0.0.0 Safari/537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8'
}
# 將 Cookie 存儲在 Session 中
session.headers.update(headers)
session.cookies['Cookie'] = cookie_value
return session
# 發出request取得網站內容或回應
def scrape_website(session, url, method = 'GET', data = {}):
if method.upper() == 'GET':
response = session.get(url)
else :
response = session.post(url, data=data, json=data)
# 檢查請求的回應
if response.status_code == 200:
# 處理回應內容
return (response.text)
else:
raise Exception(f'請求失敗,狀態碼:{response.status_code}, 錯誤訊息:{response.text}')
#發送到line通知
def line_notify(message):
try:
url = 'https://notify-api.line.me/api/notify'
data = { 'message': message }
lineSession = getSession('')
lineSession.headers = {"Authorization": f"Bearer {lineToken}"}
lineSession.headers.update(lineSession.headers)
scrape_website(lineSession, url, 'POST', data)
except Exception as error:
print(f'串接line失敗 : {error}')
# 取得使用者{id: string, name: string} | None
def getUser(session):
url = 'https://ithelp.ithome.com.tw/'
page_content = scrape_website(session, url)
soup = BeautifulSoup(page_content, 'html.parser')
account = soup.find('a', {'id': 'account'})
if account :
name = account['data-account']
href = account['href']
id = re.search(r'users/(\d+)', href).group(1)
return { 'name': name , 'id': id }
else:
return None
def editDraft(session, articlesId, Content):
draftContent = getDraftContent(session, articlesId)
url = f'https://ithelp.ithome.com.tw/articles/{articlesId}/draft'
token = draftContent['token']
newHeaders = session.headers
newHeaders['X-Csrf-Token'] = token
newHeaders['Origin'] = 'https://ithelp.ithome.com.tw'
session.headers.update(newHeaders)
subject = Content['subject']
data = {'_token': token,
'group': 'tech',
'_method': 'PUT',
'subject': subject,
'description': Content['description'],
'tags[]': Content['tags'],
}
# 將tags[]的值編碼
encoded_data = urlencode(data, doseq=True)
scrape_website(session, url, 'POST', encoded_data)
# 取得草稿列表 Array<{link:string, text: string, id:string}>
def getArticlesList(session):
user = getUser(session)
if user == None:
raise Exception('登入狀態過期,無法取得文章列表')
userId = user['id']
url = f'https://ithelp.ithome.com.tw/users/{userId}/articles'
page_content = scrape_website(session, url)
soup = BeautifulSoup(page_content, 'html.parser')
div_elements = soup.find_all('div', class_='qa-list profile-list')
if div_elements:
# 遍歷所有找到的元素,並處理它們
# 使用列表推導式篩選出包含 <span class="title-badge title-badge--draft"> 的 <div> 元素
filtered_div_elements = [div_element for div_element in div_elements if div_element.find('span', class_='title-badge title-badge--draft')]
# 檢查篩選後的結果
results = [] # 創建一個空的物件陣列來存儲結果
if filtered_div_elements:
for list_element in filtered_div_elements:
title_link = list_element.find('a', class_='qa-list__title-link')
link = title_link.get('href').strip()
text = title_link.text.strip()
id = re.search(r'articles/(\d+)', link).group(1)
result_dict = {'link': link, 'text': text, 'id': id}
results.append(result_dict)
results.reverse()
return results
else:
return []
# 取得指定草稿文章的資料內容
def getDraftContent(session, articlesId):
url = f'https://ithelp.ithome.com.tw/articles/{articlesId}/draft'
page_content = scrape_website(session, url)
soup = BeautifulSoup(page_content, 'html.parser')
input_element = soup.find('input', {'name': '_token'})
if input_element == None:
raise Exception(f'發文token取得失敗')
token = input_element['value']
subject = soup.find('input', {'name': 'subject'})['value']
description = soup.find('textarea', {'name': 'description'}).text
tag_elements = soup.find('select', {'name': 'tags[]'}).find_all('option', selected='selected')
tags = [option.text for option in tag_elements]
return {
'token': token,
'description': description,
'subject': subject,
'tags': tags
}
def publish(session, articlesId):
draftContent = getDraftContent(session, articlesId)
url = f'https://ithelp.ithome.com.tw/articles/{articlesId}/publish'
newHeaders = session.headers
newHeaders['X-Csrf-Token'] = draftContent['token']
newHeaders['Origin'] = 'https://ithelp.ithome.com.tw'
session.headers.update(newHeaders)
subject = draftContent['subject']
data = {'_token': draftContent['token'],
'group': 'tech',
'_method': 'PUT',
'subject': subject,
'description': draftContent['description'],
'tags[]': draftContent['tags'],
}
# 將tags[]的值編碼
encoded_data = urlencode(data, doseq=True)
scrape_website(session, url, 'POST', encoded_data)
message = f'已發布文章! 文章名稱: {subject} ; id: {articlesId}'
line_notify(message)
print(message)
def login(loginId, ps):
# 去登入看看
session = getSession()
url = 'https://member.ithome.com.tw/login'
loginPage = scrape_website(session, url)
soup = BeautifulSoup(loginPage, 'html.parser')
token = soup.find('input', {'name': '_token'})['value']
newHeaders = session.headers
newHeaders['X-Csrf-Token'] = token
newHeaders['Origin'] = 'https://member.ithome.com.tw'
# 將 Cookie 存儲在 Session 中
session.headers.update(newHeaders)
data = {'_token': token, 'account': loginId, 'password': ps}
response = session.post(url, data=data)
# 檢查請求的回應
if response.status_code == 200:
# 處理回應內容
if (response.cookies):
cookie_dict = requests.utils.dict_from_cookiejar(response.cookies)
cookie_string = '; '.join([f'{key}={value}' for key, value in cookie_dict.items()])
return cookie_string
else:
raise Exception(f'請求失敗,狀態碼:{response.status_code}, 錯誤訊息:{response.text}')
# 作者: 一宵三筵 (lalame888)
IT邦幫忙鐵人賽發文神器
只要貼上登入token,就可以檢視目前草稿的標題與數量
並且可開關自動發文功能,每天於設定時間(預設為10:00:00,可以更動)自動貼一篇貼文
避免失去挑戰資格
若有串接line notify
於發文後也會傳送line通知,或是程式崩潰時也會傳送通知
設定步驟:
登入IT邦幫忙主頁 : https://ithelp.ithome.com.tw/
確定已經登入之後,按下F12,然後再重整一次
這時候點到F12中的網路,找到最上方的request
查看請求(request)的標頭Header中的 Cookie
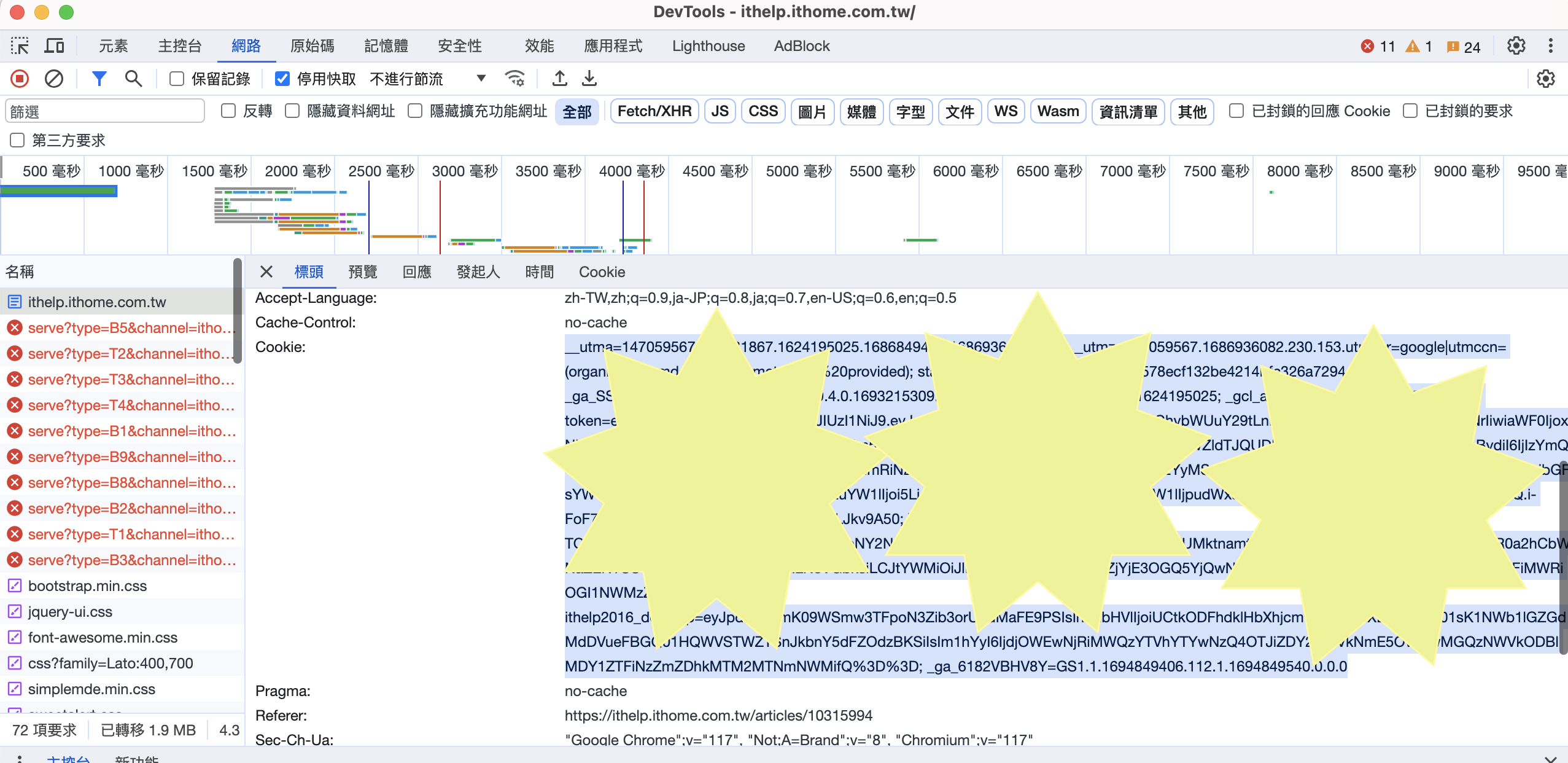
就是圖片中反白的那一大塊
複製之後,把他貼到itHelpConfig.ini中
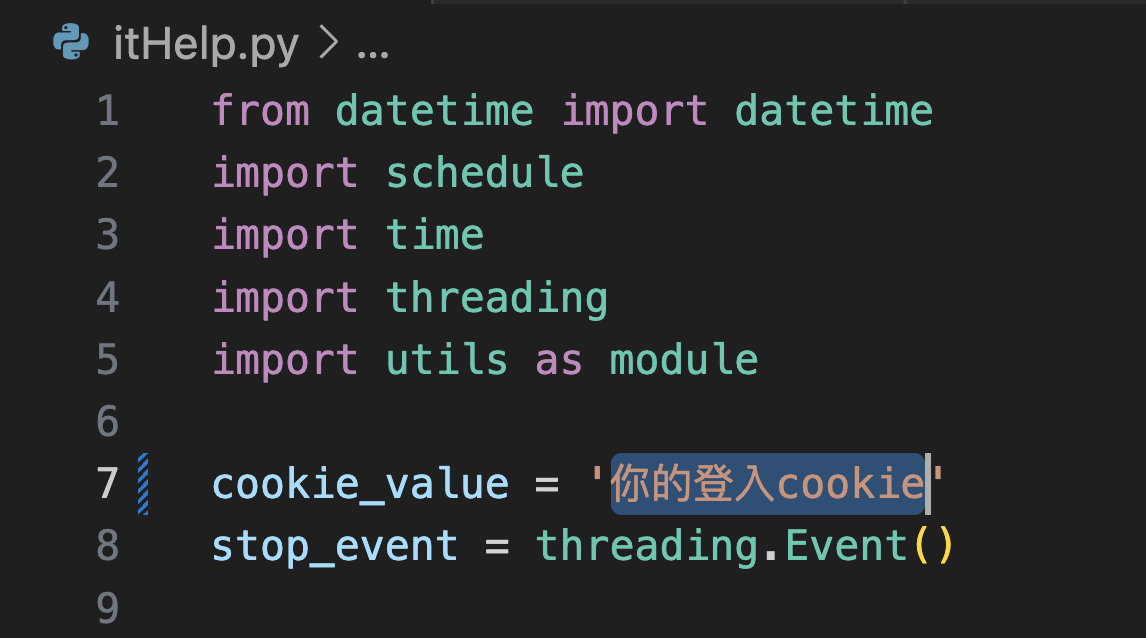
(圖片中露出來的cookie是不同的登入帳號,所以內容長不一樣正常的,單純示範)
如果希望程式起動與發佈貼文之後可以透過line傳送訊息給自己
先進入到 https://notify-bot.line.me/zh_TW/
然後登入之後,右上角名字選單點開,點擊「個人頁面」

接著頁面來到最下方,點擊發行權杖
接著輸入服務名字(看得懂是IT邦幫忙用的就好)
下方可以選擇1v1的聊天,或是可以自己創一個群組,然後把notify機器人邀進那個群組
好了之後就會得到一組token,把token複製起來
(這個示範用的token我創完就刪掉了,所以露出來沒關係)
把複製好的token,貼到itHelpConfig.ini中的line_token= 後方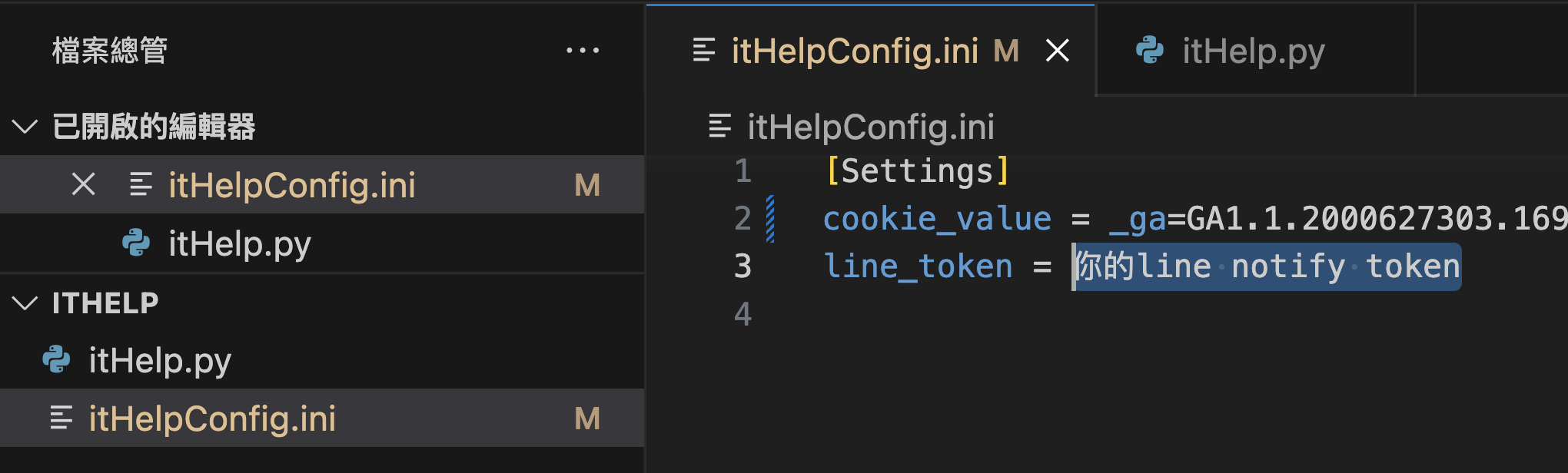
之後的通知效果會像是:
python,確認是否成功安裝。python,確認是否成功安裝。在大多數情況下,安裝 Python 的同時也會自動安裝 pip。不過,如果你確定 pip 沒有安裝或者需要更新,你可以按照以下步驟來進行安裝:
get-pip.py 腳本。可以從 https://bootstrap.pypa.io/get-pip.py 連結進行下載。你可以在瀏覽器中開啟這個連結,然後將網頁另存為 get-pip.py 檔案。get-pip.py 檔案的目錄。python3 get-pip.py
可以在終端機或命令提示字元中執行以下指令來檢查 pip 是否已成功安裝:
pip --version
如果成功安裝,將會顯示 pip 的版本號。
以下是這個專案會用到的套件:
pip install requests
pip install schedule
pip install beautifulsoup4
開啟終端機或是用VS Code等開啟專案資料夾
接著於終端機中輸入
python3 itHelp.py
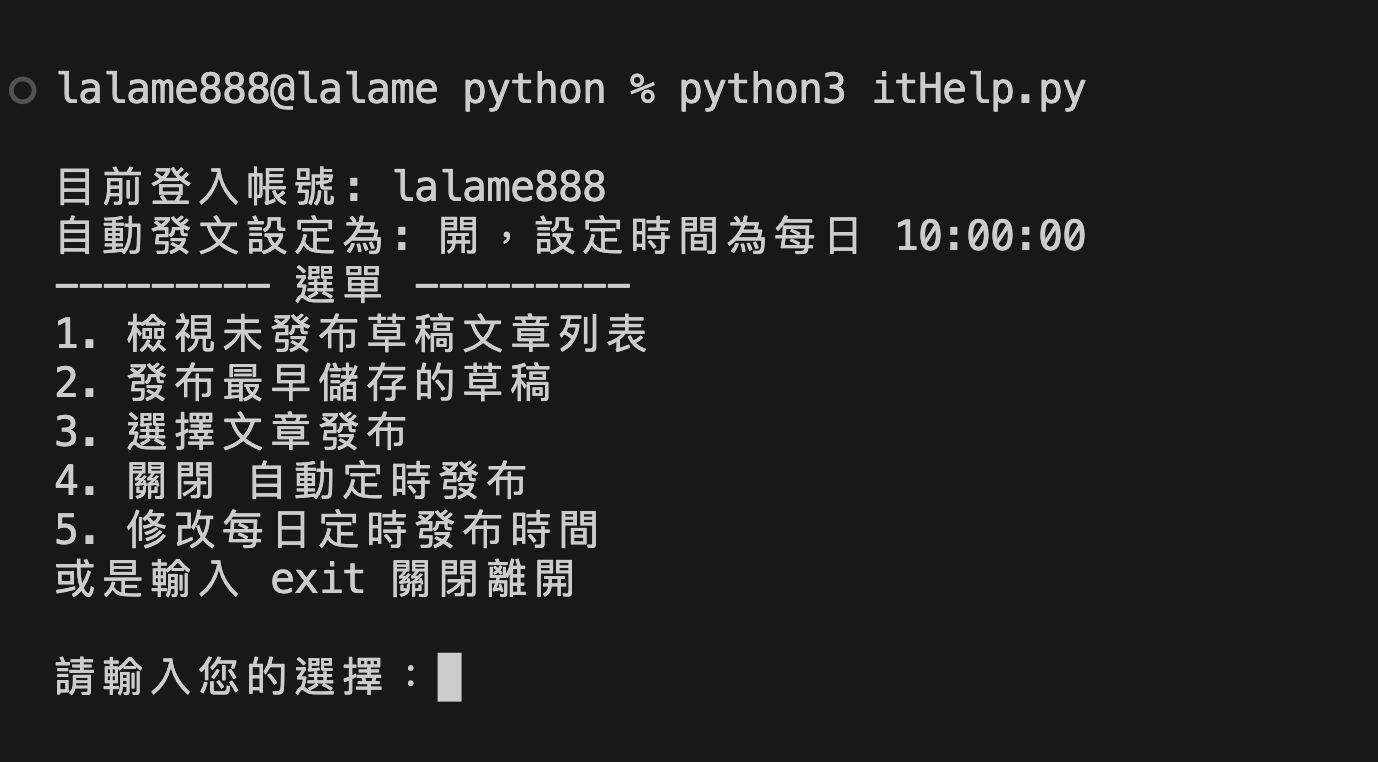
如果有串接line的話就會同步收到通知
看起來卡在選單中,但背景還是有在運作,就把終端視窗開著
這是最重要的一步,必須 「照順序」 將你要發布的草稿給儲存起來
用程式讀起來就會變成這樣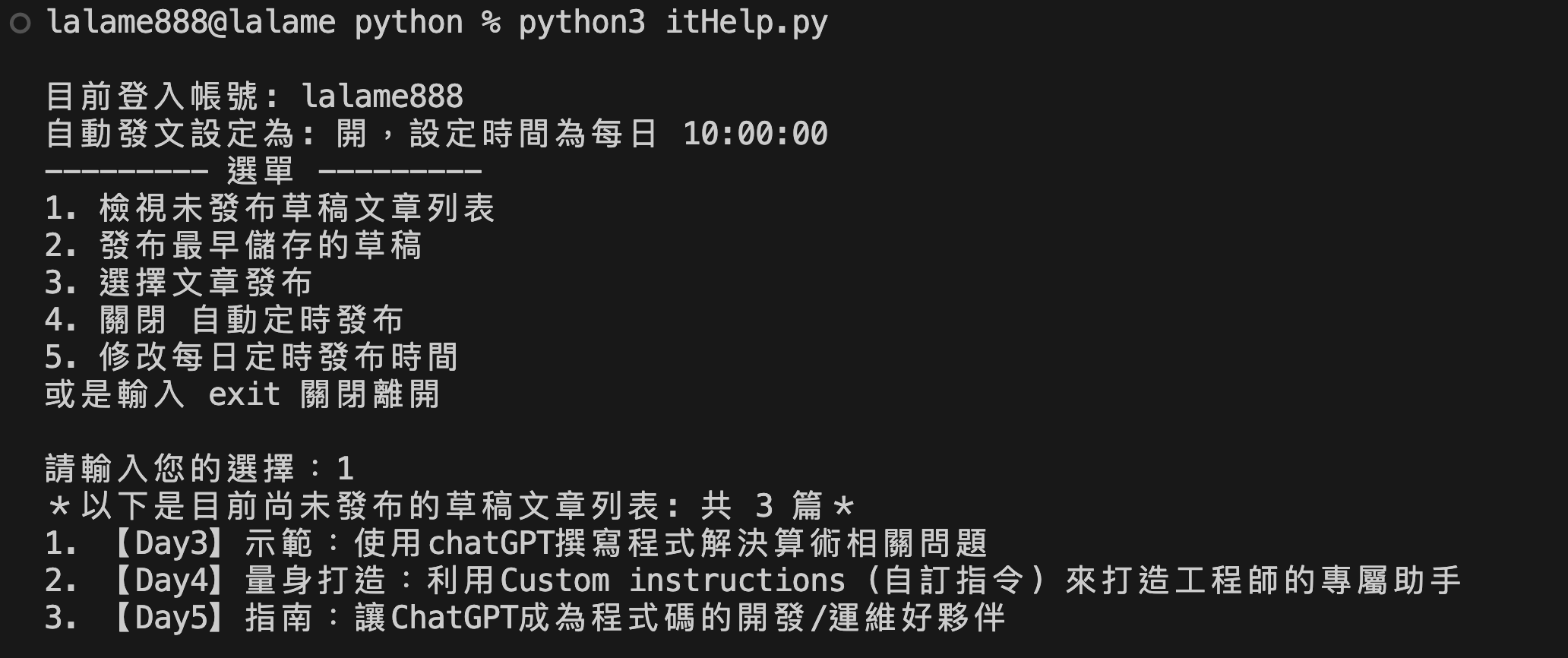
會從最早的草稿開始,當時間到就自動發文
pyinstaller --onefile itHelp.py 進行打包專案成單獨的執行檔卻一直失敗,將ini檔放在執行檔旁邊也是上面的程式說真的沒有寫得很好,我也沒有多去做整理,用兩天簡單寫完的
裡面有亂七八糟的程式碼跟全域變數跑來跑去 (對不起裡面在開副作用派對)
程式碼中,有很多片段都是我瘋狂問ChatGPT所得到的
「python陣列長度要怎麼取得」
「怎麼讓使用者輸入內容」
「eles if 在python中的語法」
「js的 `標題:${value}` 在python中要怎麼寫」
「怎麼發request、怎麼設定cookie」
「怎麼讀config」
中間狂發測試文章,那個多tag的格式真的很難搞,之後放系列文裡面
也希望小財神這兩天沒有被我的各種半夜405、419、403、500 request吵到爬起來debug...
沒有bug只是有個小王八蛋在試圖串你家的api...
it邦幫忙前端也是jQuery寫的呢,嗯。
最後,目前的專案,還有很多可以改良的地方
像是串line bot、串登入、打包成更方便直覺使用的exe等
如果有相關的教學或是要直接對程式提出改良,歡迎提出!
我是一宵三筵,再關注我的系列文章: 用ChatGPT詠唱來完成工作與點亮前後端技能樹
然後本篇內容的實作過程放在這裡
【Day54】ChatGPT幫我完成工作:不會python也能用python爬蟲做出IT邦幫忙自動發文神器
明天見~
LINE Notify SDK 參考 https://github.com/louis70109/lotify
謝謝提供~不過我看範例都是由程式端去發訊息給notify,然後line上只能傳訊息不能做互動
串notify的部分、單純傳訊息、圖片是沒問題
我想做的是可以透過line bot去遠端調整程式的設定~
例如檢視還沒發佈的草稿列表、或是修改自動發文的時間之類的
我看了你的系列文!
感覺比較是透過webhook去接受bot的訊息,以及用bot推播?
https://ithelp.ithome.com.tw/articles/10221451
這篇?
對,如果你走的入口是從 LINE Bot 的話,那就是走 webhook 去收來自 LINE 的 event,也可以參考均民大大的作法唷
如果是用python + LINE Bot 的話,可以參考看看我的 repo,主要就是用 flex message 去打 API 觸發 Github action 的動作,可以把觸發後的訊息改成你要的東西~
https://github.com/louis70109/line-bot-gitbub-actions-receiver
我晚點研究實作看看!!謝謝!太神了
https://github.com/taichunmin/ithelp-ironman-2023
這個是我做的自動發文機器人,是用 Node.js 開發的,並且使用 GitHub Actions,所以不用花錢就能用,也不需要使用自己的電腦自動發文喔!
用Github Actions去觸發定時排程好聰明!
把草稿內容貼CSV再去排程讀
也是一個好作法呢
就不用在那邊爬蟲爬半天XDD
我自己也比較熟悉nodeJS
我還沒有特別去研究那個token
那個token好像固定登入的cookie好像就是同一組?
所以要抓一次token、發文系列的ID
把他放到程式裡面的變數
整個30天看起來就可以直接跑起來了XD ?
上面python的我也發現一個問題
要一直開著自己電腦跑那個程式
而且用schedule.run_pending() 很容易程式當掉
目前測試主機如果休眠好像也會跑失敗
我現在是變成寫.bat檔去開python
跑那隻我獨立分出來的publishOnePost.py
自動發一篇預存的草稿
然後安排系統排程定時做... 這樣就還是需要一台自己電腦去跑XDD
不同系列好像也是一樣的 token,我在猜可能是跟 cookie 綁定的。
我目前的系列文章就全部都是用這個方式發文的喔 

有!我有追你了哈哈哈
發那個測試文章的時候會跑出提醒XDD
我現在先偷偷把.bat掛在公司電腦的系統排程(欸
 一宵三筵
一宵三筵
